My year 2021 in review
My professional year 2021 has been a year of Fulcro and Clojure. I have finally become a full-time Clojure developer and I have created a ton of resources for Fulcro beginners to ease and speed up their onboarding. To help them even more, while respecting the preciousness of time, I have started my company Holy Dev to provide mentoring and pair-programming to Fulcro learners. And I have written a few more essays about productivity and concepts such as simplicity on this blog.
Continue reading →
Awesome Babashka: Parse & produce HTML and SQLite
Babashka is a lightning-fast Clojure scripting tool with batteries included. It provided almost everything I needed to turn an AsciiDoctor document into a SQLite database and HTML in the format Dash - the offline documentation browser - requires to use it as a navigable, searchable "docset". While Babashka offers a lot out of the box, it can be further extended leveraging a number of available "pods" or extensions. This is a brief story of how I used Babashka to glue together Hickory, Selmer, and SQLite to make my html2dash.bb script.
Continue reading →
A light exploration of collaborative editing and synchronization algorithms
An important feature of Ardoq is that multiple users can edit the same model, i.e. a directed multi-graph. Changes from one user need to be propagated to the others and merged into their models. Collaborative editing (primarily of text) has reportedly been researched for 30 years and is still under active development. Here I share my field notes from learning about it briefly, without much tidying.
Continue reading →
What is simplicity in programming and why does it matter?

When I started with Clojure, I saw a language. Some people, when they look at it, they only see a weird syntax. It took me years to realize that in truth Clojure is a philosophy. The language embodies it, the ecosystem embraces it and grows from it, you the developer eventually soak it up.
The philosophy is simplicity - on a very profound level - and, to a lesser degree, ergonomics [1]. What do I mean by simplicity and ergonomics? Simplicity is about breaking things apart into their elementary constituents that are orthogonal to each other. Ergonomics is about making it possible and convenient to combine these elements in arbitrary, powerful ways. You end up with simple things that have single responsibility and that you can combine freely to suit your unique needs. These elements are simple but also generic and thus applicable in many situations and usable in many ways. This is crucial also for flexibility:
Continue reading →
Clojure is frustrating... and it is a good thing
n 2016, the Clojure core team announced Clojure Spec, the most important addition to Clojure since v1.0.0. Spec allows you to describe and verify the shape of data (and much more) in a somewhat unique way. Having experienced developing a webshop from scratch in the dynamically typed JavaScript/Node.js, with the code growing in complexity and team in size, I very much appreciated the value of describing and checking data against a schema at important points of the program (without being swamped by doing it everywhere). In 2018 Rich Hickey in his talk Maybe Not discussed some shortcomings of Spec - some of which I have experienced personally - and work on Spec 2 started to address those and some limitations. I was fired up because Spec was great - and Spec 2 seemed to be perfect. I waited, and waited, … and waited. It is 2021 and Spec 2 is still nowhere in sight. That is truly frustrating. Similarly it has been with other design developments in Clojure such as named arguments. And it is, despite all my frustration, very, very important that it is this way.
Continue reading →
Specific vs. general: Which is better?
If you want your blog’s tag list to also show the tags' frequency, what is better? Adding the very specific feature of frequency computation to the blog engine or making it possible to supply a custom function that takes the whole program state and can return a new version of it (including e.g. tag frequencies)? I want to argue that in this case the latter is far superior.
Continue reading →
Productivity killers in enterprise programming - and how to overcome them

This article is about "the death [of productivity] by thousand cuts" - about the many obstacles that make enterprise development unnecessarily slow, costly, and painful. And it is about the "invisible cost" of ignoring them. I look at the top obstacles that we encounter and at what we could do about them. I argue that we must prioritize great developer experience and invest into our tools and into simplicity - and that this will yeld benefits both to developers and to the business. Those in power need to realize that developer happiness isn’t about perks, huge monitors, and relaxation pods (though those would be cool!). It is, to a large extent, about our ability to do our job without hindrances and thus it is about delivering more value, faster.
Continue reading →
Slow restarts are killing your productivity. Can Clojure save you?
Our Java and Spring webapp may take 5-10 min to restart after a change on my PC, especially when something else (such as IntelliJ) is using the CPU. On Friday I was trying to factor out a new endpoint and it took me about three attempts to get it right. Every time I had to wait for the behemoth to restart to discover that my code was still broken.
And that is why I love Clojure with its interactive development, which provides me an immediate feedback. You could argue that if only I knew Spring better and were a better programmer, I could have made the change right the first time. And you would be right. But I am not that good and, even though I like learning, I do not feel like learning Spring perfectly before coding anything. (I would actually prefer not to have to learn Spring at all, but that is another story.)
Continue reading →
Fulcro Explained: When UI Components and Data Entities Diverge
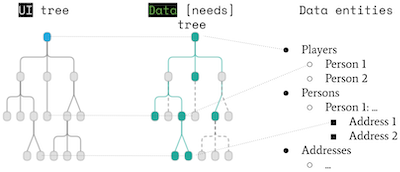
Fulcro’s stateful components serve normally both as elements of the UI and to define the data model, i.e. data entities with their unique IDs and attributes. And that is what you want 95% of the time. But what if your UI and data model needs diverge?
We will take a look at what different kinds of divergence between the UI and data entities you might encounter and how to solve them.
Updated: 2021-11-6
Continue reading →
Customizing the Gradle run task
The Gradle application plugin provides you with a run task to run your Java application (provided you have set the mainClassName). But how do you customize it, e.g. by setting extra JVM arguments? No amount of searching helped me so I want to share what I have learned.
The run task is of the type JavaExec and accepts the same settings, such as args, debug, debugOptions, jvmArgs, environment, systemProperties. And you can configure it simply by declaring it:
Continue reading →
The best team ever
What makes a great team? How to make our teams great? I want to contribute to the answer by sharing the experience of the best team I have ever been on. This team of 3 + 2 has challenged the established way of working, bringing development in-house and together with the business, replacing a shelf product with a purpose-built one, going from on-premise to the cloud and from e-mail to Slack, from Java to JavaScript, with the first production release being a single product page "pasted" on top of the existing application. We were productive and happy.
So what was so great about this team? In short - problem, people, power (and fun).
Continue reading →
Spring Framework: Why I prefer a simpler solution nowadays
 Once upon a time, the Spring Framework provided a much more lightweight and flexible solution than J2EE. Even in around 2013 I was happy to learn in detail about the then new Spring 4. Nowadays, 7 years later, when I see Spring, I get a panic attack. Annotations and
Once upon a time, the Spring Framework provided a much more lightweight and flexible solution than J2EE. Even in around 2013 I was happy to learn in detail about the then new Spring 4. Nowadays, 7 years later, when I see Spring, I get a panic attack. Annotations and @ComponentScan have replaced XML with something nicer - that requires a visualization tool to understand your system. And Spring has become a hydra that keeps on growing (and changing) heads. I have suffered through taking over and trying to understand a Spring application written by others. And, last but not least, Clojure has taught me how simple code can/should be. So what are my main issues with Spring?
Continue reading →
Want more from your frontend framework! Re-thinking web dev experience
An extended transcript of my talk at DevFest Norway 2020 (slides here).

Do you also love creating useful (web)apps and get easily frustrated by any friction in the development process? I will compare Redux + REST with a full-stack, component-centric solution based on a graph API (think GraphQL) that I came to love. You might not be able to use the same framework - Fulcro - but you can still look for similar, more developer-friendly solutions that implement some of the same ideas and provide some of the same functionality. We will discuss REST vs. Graph APIs, networking, error handling, and more. (You should have an idea about React, Redux, and GraphQL to gain most out of this.)
Continue reading →
On crafting troubleshooting-friendly responses in web apps
Once again I have wasted 1-2 hours trying to figure out where the damn "403 Forbidden" was coming from. Yet, with a little forethought and a few seconds or minutes of time, hours could have been saved on such cases. This one would have been trivial if this was already in place, instead of the original, spartan response.sendError(403):
response.addHeader("X-Authority", "HomeController")
response.sendError(403, "Access to the app (temporarily) disabled for everybody")I would know to look into HomeController and that there is no problem with that particular user’s credentials. I could also search the code for that error message.
In total I have certainly spent days hunting for the source of HTTP errors, especially auth-related ones. So I beg you, when you write any error-handling or secondary-flow code, think about the poor person who is going to troubleshoot it and give her - likely your future self - friendly hints instead of ugly, useless 403 Forbidden / 401 Unauthorized / 500 Internal Server Error / …. Let’s have a look at what you can do to prevent a lot of frustration and wasted time.
Continue reading →
Error handling in Fulcro: 3 approaches
I present three ways of detecting, handling, and showing server-side errors: globally and at the component level.
By default, Fulcro considers only non-200 HTTP status as an error. It is up to you to tell it what is an error and how to handle it.
This is somewhat controversial - as Programming with Pure Optimism in the Fulcro Developers Guide explains:
A server should not throw an exception and trigger a need for error handling unless there is a real, non-recoverable situation.
And, as Tony explained elsewhere (paraphrasing):
Make sure resolvers never throw, and have them return errors as first-class data. Only (detectable) security hacks and (unexpected) bugs should be hard-core errors. Intentional behavior of your server should always return a sensical value for a query, which may in fact simply be something like: “form save failed”. In that case components can query for problems with a real query prop, and each resolver can populate that key with an error if it has one. So, if you want to do component-level error handling, just adopt that philosophy and make
remote-error?assume that something serious went wrong and the user probably should call support, reload the page, and perhaps even log back in. (You can for example define your owndefresolvermacro that automatically adds error handling.)
In my case, I have an internal application and I encounter mostly bugs and downstream service issues so this approach is a better fit for me than if I had a public-facing application.
Continue reading →