Hands on Rama, day 2: Rewrite CAS, finish basic C(R)UD
My adventures with Rama continue from day 1. In the second day, I rewrote the compare-and-set logic to atomically succeed only if all field edits were ok (instead of on per-field basis), and I finished my basic, idempotent C(R)UD, with full test coverage. I have re-learned that no special forms may be used in dataflow code. Instead, I may write top-level functions or create anonymous rama fns via <<ramafn. I have also been reminded that code called from dataflow must not throw exceptions.
I actually took a long break between my first and second day of coding, because the first one taught me that I really needed to understand Rama in much more detail. So I have read essentially the whole Java-focused docs, as well as Clojure ns docstrings, especially those for paths. Since I am me, I forgot a lot and will need to re-read it, but anyway writing Rama is now much simpler.
Overall, it was pretty smooth sailing, even though I had some rough spots, as you can read below.
Continue reading →
My year 2023 in review
This has been a good year: I have been to my first (and likely last) Conj, where I met a couple of my Clojure heroes and old and new friends. I have finally held my "Why Fulcro, and how to learn it efficiently" talk at London Clojurians. After some 9 months, I have finished and fully "productionalized" my tiny ERP, powered by Fulcro RAD and (nowadays) Datomic. RedPlanetLabs have released its "100x productivity backend programming platform," and I am exploring it. Better late than never, I have started bringing the mind-bending Wolfram to Clojurians via Wolframite.
Continue reading →
Hands on Rama, day 1: Setup, idempotent create & update
This is a part of a series documenting my experience applying the Rama programming platform to reimplement a part of the SaaS Ardoq, as a learning exercise. In day 1, I get set up and implement idempotent create and update of Components, while struggling with a few issues and lack of knowledge.
Introduction
I want to learn the amazing programming platform Rama by applying it to a problem I know well: Ardoq. Ardoq is a SaaS tool for enterprise architects and others, to map and model the resources, processes, assets, and strategy in an organization. The heart of Ardoq is a property multi-graph: a directed graph with multiple directed edges between nodes, and with an arbitrary bag of properties attached to nodes and edges.
There is of course no way to rewrite Ardoq in Rama in one person in a few days. Instead, I want to explore two things: (1) How can I model, store, and manage our core data in Rama instead of a relational database? (2) How does Rama make a few selected features simpler/harder to write?
Continue reading →
Exploring Rama, the platform for writing backends 100x more efficiently
In 8/2023, RedPlanetLabs has unveiled Rama, their integrated platform for writing and operating robust, distributed, and scalable backends 100x more efficiently. With it comes a new paradigm - dataflow oriented programming. So what is it all about?
In this post I aim to give you a rough idea of what Rama is, what it offers, and why you absolutely should be interested in it.
Continue reading →
PostgreSQL & JDBC: How to select rows matching pairs of values
Given a sequence of pairs of (id, version) in code, how do you efficiently select all records in your DB that match? You can construct a long string with SELECT … WHERE (id = 'a' AND version = 1) OR (id = 'b' AND version = 20) OR … but that’s not very efficient. If you only had a single value then, in PostgreSQL, you could use id=ANY(?) and pass in a char array. But what if you have multiple conditions/columns that must match? Unnest to the rescue!
Continue reading →
The Four Heads of Complexity
Kent Beck has recently written about the four distinct aspects of complexity: states, interdependencies, uncertainty, and irreversibility. To tame complexity, you need to cut off one of these heads, and keep the others under control. What are they?
If there is too many states and their combinations in the system, it becomes hard to understand.
Continue reading →
Include interactive Clojure/script code snippets in a web page with SCI & friends
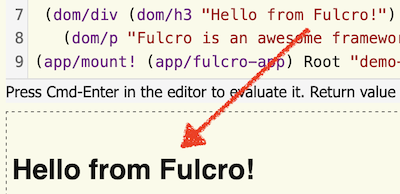
I have long dreamt about having interactive code snippets of Fulcro in my teaching materials. Showing people code they could modify and see it render right next to it. Fulcro is a ClojureScript library, but it uses some heavy macros - and those typically require JVM Clojure. Well, not anymore. I was able to rewrite them into Borkdude’s Small Clojure Interpreter (SCI) dialect of Clojure. I.e. I can ask SCI to evaluate a piece of code with these macros, which SCI will macro-expand into more cljs, and execute. With SCI, my Fulcro sci.configs, CodeMirror, and Nextjournal’s clojure-mode, I can have a beautiful in-page editor with code evaluation. And I will show you how to do the same, for your blog.
Continue reading →
Accessing Google API with OAuth2 and a service account from Clojure
How to turn a service account’s service.json into an access token you can actually use to call Google APIs, when you don’t want to use Google’s SDK? With Buddy’s JWT it is pretty simple, and Tim Pratley’s HappyGAPI will show us how to do it. (I believe that the same approach would work with other OAuth providers, just with changes to some of the values.)
Continue reading →