Book Review & Digest: Release It! Design and Deploy Production-Ready Software
By Michael T. Nygard, 2007, ISBN: 978-0-9787-3921-8
My digest and review of the book.
Of the books I have read, Release It! is the one I would require all "senior" developers to read (together with something like Architecting Enterprise Solutions: Patterns for High-Capability Internet-based Systems). Especially the first part on stability with its patterns and anti-patterns is a must read. Without knowing and applying them, we create systems that react to problems like a dry savannah to a burning match. I found also to next to last chapter, #17 Transparency, very valuable, especially the metrics and design of the OpsDB and observation practices.
One thing I have left out of the digest which is really worth reading are the war stories that introduce each section, they are really interesting, inspiring, and educational.
Stability x longevity bugs
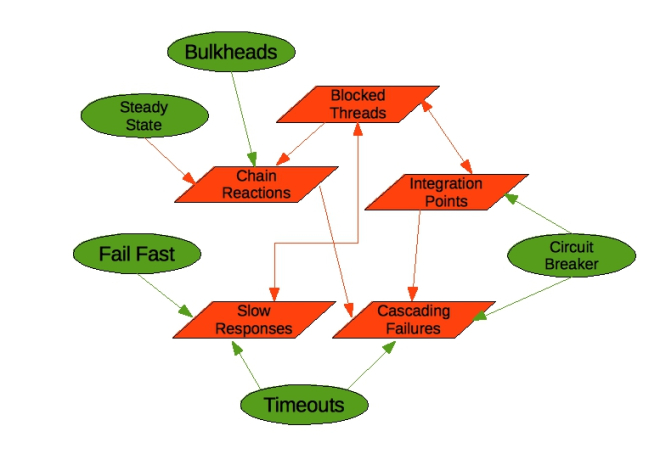 Selected (anti)patterns
Selected (anti)patterns
Integration point = call to a DB, WS, ... . Stability risk #1.
Load-balanced application with a defect (typically resource leak or load-related crash). If the defect is triggered in one instance and it fails, the remaining ones are the more likely to fail (increased load, ...). Bulkheads can help by splitting nodes into separate sets with separate, smaller chain reactions occuring hopefully at different times. Can lead to a cascading failure in a calling layer.
= problems in one layer cause problems in callers - often due to drained resource pools
Ex.: An email from marketing to a selected user group with a special deal – which they will share further and suddenly the page if flooded by users. All servers waiting to acquire a lock to update the same, popular item (=> prefer shared-nothing architecture or at least apply decoupling middleware or make the shared resource itself horizontally scalable through redundancy and a synchronization protocol).
Something that worked in small scale leads to problem when the system is scaled up. Whenever we have a many-to-one or many-to-few relationship, we might run into problems when the “more” side increases, f.ex. the DB may crash when going from 2 AS – 1 DB to 10 AS – 1 DB. A common problem is point-to-point communication.
U.C. is a special case of Scaling Effects: one side of a relationship scales up much more than the other side. Ex.: Many web servers that typically serve mostly static content and only few dynamic pages provided by back-end servers; if the traffic pattern (workload) suddenly changes, i.e. many users coming to the dynamic functionality, the front-end servers will flood the few back-end ones. It might be impractical to match their capacities for rare spikes so build them both to be resilient in the face of a tsunami of requests. For the front-end, Circuit Breaker will help by relieving the pressure on the back-end when responses get slow or connections get refused. For the back-end, use Handshaking to inform the front-end to throttle back on the requests. Also consider Bulkheads to reserve capacity on the back-end for other transaction types.
Generating a slow response is worse than refusing a connection or returning and error as it ties up resources in both caller and callee. They usually result from excessive demand or due to an underlying problem, f.ex. memory leaks and the resulting garbage collection, network congestion.
SLA Inversion = a system that must meet a high-availability SLA depends on systems of lower availability. But the best SLA you can provide is the one of your dependency with the worst SLA.
Solution: 1) Decouple from the lower SLA systems so that your app can continue functioning without them, degrade gracefully. Decoupling middleware is excellent for this. At least employ circuit breakers to protect from your dependencies. 2) Determine a realistic SLA and, instead of the whole system, focus on the availability of specific functions/features w.r.t. their dependencies.
Ex.: Allow customers to continue purchasing even when delivery scheduling isn't available.
"Design with skepticism, and you will achieve. Ask, 'What can system X do to hurt me?' and then design a way to dodge, duck, dip, dive, and dodge whatever wrench your supposed ally throws." p95 One of those systems is your DB - what if it suddenly returns 5M rows instead of the usual hundreds?
Rarely you want to wait forever (or many minutes).
HttpClient example:
A Circuit Breaker wraps an Integration Point and works like a fuse, "melting" (opening) when a number of calls to the system fail or time out in a row, thus making subsequent request fail fast without consuming too much resources and easying load on the remote systems. Occassionally it lets a call through to check whether the system hasn't become responsive again.
It works great with graceful degradation, i.e. offering limited yet still useful functionality to users when a subsystem becomes unavailable.
MSDN's Circuit Breaker Pattern page is pretty good. Martin Fowler's introduction of Circuit Breaker with a simple example implementation in Ruby and useful links.
Impl. in Java with Spring AOP and JMX: https://code.google.com/p/jianwikis/wiki/CircuitBreakerDesignPattern, Clojure implementation.
Bulkheads are water-tight compartments in a ship; when there is a hole, water floods only one compartment, saving the ship from sinking. Similarly you may partition your resources (servers etc.) and assign the partitions to particular clients/functions so that a failure doesn't affect all and/or more important functionality/clients are protected from failures triggered by less important ones. Physical redundancy is the most common form, protecting from HW failures. A small-scale example is binding a process to only a subset of CPUs. Inside of a process, you might create separate thread groups dedicated to different functions - f.ex. separate request-handling thread pool for administrative functionality. Ex.: A failure in flight status functionality won't stop check-in from working.
For every mechanism that accumulates a resource (data in a DB, log files, memory consumed by a cache), some other mechanism must recycle that resource.
If a system can determine in advance that it will fail in an operation, it's better to fail fast.
A well-done middleware integrates (by passing data and events) and decouples (by hiding specific knowledge, calls to other systems) systems.
Scale:
Same host, time, process
Different time, host, process
Quiz - what is wrong here:
User sessions are the Achilles heel - they consume memory, and, if replication enabled, CPU and bandwidth.
Load testing: real world isn't polite to the site. Search engine spiders may ignore cookies create a new session on each request (while generating many requests). Scrapers and shopbots do the same.
=> don't test the system just the way it is meant to be used
Useful tools
Capacity myths: CPU, bandwidth, and storage are cheap.
"Used well, [DB] connection pools, like all resource pools, can improve capacity by improving throughput. Left untended, however, resource pools can quickly become the biggest bottleneck in an application." [167] - when there is contention for the resource , i.e. less than needed available; the requesting thread is then blocked indefinitely. Also, each connection - even whine idle - consumes resources on the remote system.
Ajax = many more requests coming from the browser to the server, more rapidly. The req and resp will typically be smaller. Used poorly, it will place more burden on the web an app servers.
Session thrashing - ensure session affinity so AJAX req go to the server having the user's session. Make sure you don't create a new session for each req.
How long a session stays in mem after the last req (as we have now way of knowing the user went away for good) - defaul(ed) to 30min in Java. Look at your data to determine session timeout: e.g. avg + 1 std dev. In practice it will be ~ 10 min for a retail site, 5 min for a media gateway, up to 25 for travel-industry sites. Even better is to make sessions unnecessary. F.ex. in-mem copy of persistent data may be dropped and recreated at any time (keep keys, not whole objects).
Every byte consumes bandwidth, memory, processing resources on different networking equipment and the servers. Omit needless characters, remove whitespace, replace HTML tables with CSS layout.
If the site is slow, users may start hitting Reload in hope of getting a presumabely stuck response, thus increasing the load even more. (The app server doesn't know it should stop processing the previous one.) Make your site fast so that users never think of doing this.
ORM => predictable, repetitive SQL. Predictable access patterns of SQL are good for capacity, b/c a competent DBA can tune the DB for them. OO developers suck at relational queries and create expensive queries inconsistent with the tuning for the rest of the app.
Common problems: joins on non-indexed columns, joining too many tables, .. .
=> minimize, check with a DBA, verify gains against real data.
=> keep cookies small; they're sent with every request.
Use & remember to protect callers from blocking forever. Size them for max throughput.
Limit cache sizes. Build a flush mechanism. Don't cache trivila objects. Compare access and change frequency.
Not everything needs to be dynamic and even not all the dynamic stuff changes equally often.
"In Java applications, garbage collection tuning is the quickest, and easiest way to see some capacity improvements. An untuned application running at production volumes and traffic will probably spend 10% of its time collecting garbage. That should be reduced to 2% or less." [205] (Remember this was written in 2007.)
Topics: Multihomed servers, getting routing right, virtual IP addresses.
Topics: The Principle of Least Privilege (separate user/app, ...), Configured Passwords (separately in encrypted files, ...).
Gathering and documenting requirements (refer to these whenever responsible for defining availability!), load balancing, reverse proxying, clustering .
Keeps app separated if sep. in prod to prevent hidden dependencies. Zero, One, Many - if having many nodes in prod, have 2 in QA. Just buy the gear: "I've seen hours of downtime result from presence of firewalls or load balancers in production that did not exist in QA." [238]
Build a clear start-up sequence into the app so that everything starts in the right order and must complete before requests are served. Init. at least some conn for each conn. pool (Fail Fast).
Clean shutdown: have a mode where existing tx are completed (remember a timeout) but new request not accepted.
CLI interfaces for administration are best (<> scripting) x GUIs.
= qualities allowing personnel to gain insight into the system's historical trends, present conditions, instantaneous state, and future projections.
Start early. You need visibility into the whole system to avoid local optimization.
Standards
What to expose
Logging & monitoring expose the immediate behavior/status but unsuitable for the historical/future perspective => accumulate status, metrics in a (ops) DB.
OpsDB high-level structure
Eventually we add:
Expectation = an allowed range for a metric, a time frame in which an event must [not] occur, an allowed status; violation => alert. Set based on historical data. (Beware false positives = crying the wolf!). Eventually the expectation values may become functions of the business rhythm (day/night, special seasons, ...)
Build an effective feedback process, i.e. only share meaningful data that is act on responsively . See Plan-Do-Check-Act, Boyd's OODA etc.
Watch for both trends and outliers. Include continuous improvement.
The emphasis shifts from reactive to predictive. Old metrics/reports loose value.
For each metric being reviewed: How does it compare to the historical norms? If the trend continues, what happens to the correlated metric (# users x responsiveness); how long can it continue before hitting a limiting factor and what will happen then? => interpretation & decisions
Topics: Adaptatable SW design, dependency injection, object design, XP coding practices, agile DBs, adaptable enterprise architecture, dependencies within a system, d. between systems: protocols/DBs, releases shouldn't hurt (0 downtime deployments, ...)
My digest and review of the book.
Review
Of the books I have read, Release It! is the one I would require all "senior" developers to read (together with something like Architecting Enterprise Solutions: Patterns for High-Capability Internet-based Systems). Especially the first part on stability with its patterns and anti-patterns is a must read. Without knowing and applying them, we create systems that react to problems like a dry savannah to a burning match. I found also to next to last chapter, #17 Transparency, very valuable, especially the metrics and design of the OpsDB and observation practices.
One thing I have left out of the digest which is really worth reading are the war stories that introduce each section, they are really interesting, inspiring, and educational.
Extra Links
- Release It! slides: http://gotocon.com/dl/jaoo-sydney-2009/slides/MichaelT.Nygard_FailureComesInFlavoursPart2.pdf
- https://github.com/Netflix/Hystrix/
- Netflix's Dependency Command talks about using circuit breakers and a thread pool limit http://techblog.netflix.com/2012/02/fault-tolerance-in-high-volume.html
- MSDN Guidance for Cloud Applications: Design Patterns - Circuit Breaker and many more highly useful patterns
Stability
Stability x longevity bugs
Selected (anti)patternsStability antipatterns
Integration points
Integration point = call to a DB, WS, ... . Stability risk #1.
- Every will eventually fail
- Many possible errors: network, application, ...
- Symptomps: protocol violation, slow response, hang, abruptedly closed connections, ...
- Be defensive to prevent cascading failures when the remote system is having problems - Circuit Breaker, Timeouts, Decoupling Middleware, Handshaking; use Test Harness to test
- Ex.: connections refused (catch: it can take a long time to find out that you cannot connect, f.ex. when it is listening but unable to process requests or when ACKs do not arrive and it keeps on retrying); a firewall may throw away an old connection without telling anyone, silently dropping packets
Chain Reactions
Load-balanced application with a defect (typically resource leak or load-related crash). If the defect is triggered in one instance and it fails, the remaining ones are the more likely to fail (increased load, ...). Bulkheads can help by splitting nodes into separate sets with separate, smaller chain reactions occuring hopefully at different times. Can lead to a cascading failure in a calling layer.
- One server down jeopardizes the rest
- Hunt for resource leaks
- Hunt for obscure timing bugs - traffic can trigger obscure race conditions; if a deadlock kills a server then increased load on the remaining ones is more likely to trigger it as well
- Defend with Bulkheads, use Circuit Breaker on the caller's side
Cascading Failures
= problems in one layer cause problems in callers - often due to drained resource pools
- Be paranoid about Integration Points
- C.F. often results from a resource pool that gets exhausted when threads check out the resource and get blocked because their call never returns and other threads wait for the resource. A safe resource pool should always limit the time a thread can wait to check out a resource.
- A Circuit Breaker protects your system by avoiding calls out to the troubled Integration Point, using Timeouts ensures that you can come back from a call out to the troubled one
Users
- Users consume memory => minimize session size, use session only for caching so that you can purge its content if memory gets tight (and re-create when needed again). F.ex. in Java use SoftReferences. Beware that session lives until last interaction + timeout, which defaults to 30 min (multiply that by too many users ...)
- Users do weird, random things, don't expect them to behave as you expect; if there is a weak spot, they'll find it
- Malicious users are out there - keep up-to-date, prevent SQL injection etc.
- Sometimes users come in really, really big mobs => hangs, deadlocks, obscure race conditions; run special stress tests to hammer deep links or hot URLs
- Beware artificial users such as bots and indexing spiders - they do many requests in no time, may ignore cookies (=> each one results in a new session)
Blocked Threads
- f.ex. When checking out resources from a connection pool, dealing with caches or object registries, making calls to external systems,or synchronizing threads
- The Blocked Threads pattern is the proximate cause of most failures; the lead to Chain Reactions and Cascading Failures
- Scrutinize resource pools – threads often blocked on them; f.ex. a deadlock in a DB or incorrect exception handling (and thus a failure to release a connection)
- Use proven primitives for concurrency instead of creating your own (see
java.util.concurrent) - Defend with Timeouts so that no deadlock lasts forever – always use them
- Beware the code you cannot see – f.ex. in libraries
Attacks of Self-Denial
Ex.: An email from marketing to a selected user group with a special deal – which they will share further and suddenly the page if flooded by users. All servers waiting to acquire a lock to update the same, popular item (=> prefer shared-nothing architecture or at least apply decoupling middleware or make the shared resource itself horizontally scalable through redundancy and a synchronization protocol).
- Be informed – make sure that if there is a marketing campaign, you know about it. Make sure it doesn't use deep links (bypassing your caching proxy), watch our for embedded session Ids in URLs. Create a static “landing zone” pages for the first click from these offers.
- Protect shared resources in the case of traffic surges. Watch out for increased front-end load causing exponentially increasing back-end processing.
- Expect rapid redistribution (i.e. spreading wide and far) of any cool or valuable offer – there is no such thing as distribution to a limited user set
Scaling Effects
Something that worked in small scale leads to problem when the system is scaled up. Whenever we have a many-to-one or many-to-few relationship, we might run into problems when the “more” side increases, f.ex. the DB may crash when going from 2 AS – 1 DB to 10 AS – 1 DB. A common problem is point-to-point communication.
- Examine scale differences between production and QA environments to spot Scaling Effects – patterns that work fine in small environments or one-to-one environments might slow down or fail completely when you move to production sizes
- Watch out for point-to-point communication – it scales badly since # connections increases as the square of participants
- Watch out for shared resources – they can be a bottleneck, a capacity constraint, and a threat to stability. If you have one, stress test it heavily. Make sure its clients will keep working if it gets slow or locks up.
Unbalanced Capacities
U.C. is a special case of Scaling Effects: one side of a relationship scales up much more than the other side. Ex.: Many web servers that typically serve mostly static content and only few dynamic pages provided by back-end servers; if the traffic pattern (workload) suddenly changes, i.e. many users coming to the dynamic functionality, the front-end servers will flood the few back-end ones. It might be impractical to match their capacities for rare spikes so build them both to be resilient in the face of a tsunami of requests. For the front-end, Circuit Breaker will help by relieving the pressure on the back-end when responses get slow or connections get refused. For the back-end, use Handshaking to inform the front-end to throttle back on the requests. Also consider Bulkheads to reserve capacity on the back-end for other transaction types.
- Examine, compare server and thread counts, especially in Prod vs. QA
- Observe near scaling effects and users
- Stress both sides of the interface; if you hammer the back-end with 10* more requests than historical max on its most expensive transaction, does it fail or slow down and eventually recover? What does the front-end do when the back-end stops responding or gets very slow?
Slow Responses
Generating a slow response is worse than refusing a connection or returning and error as it ties up resources in both caller and callee. They usually result from excessive demand or due to an underlying problem, f.ex. memory leaks and the resulting garbage collection, network congestion.
- Slow Responses triggers Cascading Failures, the upstream system will too slow down and become vulnerable to stability problems
- For websites, Slow Responses causes more traffic as users hit "reload"
- Consider Fail Fast - f.ex. if your SLA requires response in 100ms and a moving average over the last 20 calls exceeds it, you can start refusing requests (the upstream system must be prepared for that)
- Hunt for memory leaks or resource contention (f.ex. too few DB connections)
SLA Inversion
SLA Inversion = a system that must meet a high-availability SLA depends on systems of lower availability. But the best SLA you can provide is the one of your dependency with the worst SLA.
Solution: 1) Decouple from the lower SLA systems so that your app can continue functioning without them, degrade gracefully. Decoupling middleware is excellent for this. At least employ circuit breakers to protect from your dependencies. 2) Determine a realistic SLA and, instead of the whole system, focus on the availability of specific functions/features w.r.t. their dependencies.
Ex.: Allow customers to continue purchasing even when delivery scheduling isn't available.
- For every service, your system depends on transport layer availability, naming services (DNS), and application-level protocols and any of these can fail.
- If built naively, the probability of failure of your system is the joint probability of a failure in any component or service so P(up) = (1 - P(internal failure)) * P(dependency 1 up) * ... * P(dependency N up). So for five dependencies with 99.9% availability we can get at most 99.5%.
Unbounded Result Sets
"Design with skepticism, and you will achieve. Ask, 'What can system X do to hurt me?' and then design a way to dodge, duck, dip, dive, and dodge whatever wrench your supposed ally throws." p95 One of those systems is your DB - what if it suddenly returns 5M rows instead of the usual hundreds?
- Use realistic, production-sized data volumes in testing/dev
- Don't rely on the data producers to create a limited amount of data
- Put limits into other application-level protocols: WS calls, RMI, XML-RPC, ... are all vulnerable to returning huge collections of objects, thereby consuming too much memory (and keeping on working long after the user has lost interest)
- Unbounded result sets are a common cause of Slow Responses; they can result from violation of Steady State
Stability patterns
Use Timeouts
Rarely you want to wait forever (or many minutes).
- Apply to Integration Points, Blocked Threads, and Slow Responses; they prevent calls to I.Points from becoming Blocked T. and thus avert Cascading Failure.
- Combine with Circuit Breaker (trigger when too many) and Fail Fast (to inform your callers you are not able to process requests).
- Apply to recover from unexpected failures - when an operation is taking too long, we sometimes do not care why, we just need to give up and keep moving
- Consider delayed retries - the network or remote system problems causing them won't be resolved right away so immediate retries make it only worse and make the user wait even longer for the inevitable failure response.
HttpClient example:
RequestConfig.custom()
.setConnectionRequestTimeout(1000).setConnectTimeout(1000).setSocketTimeout(1000).build();Circuit Breaker
A Circuit Breaker wraps an Integration Point and works like a fuse, "melting" (opening) when a number of calls to the system fail or time out in a row, thus making subsequent request fail fast without consuming too much resources and easying load on the remote systems. Occassionally it lets a call through to check whether the system hasn't become responsive again.
It works great with graceful degradation, i.e. offering limited yet still useful functionality to users when a subsystem becomes unavailable.
- Don't do it if it hurts - C.B. is the fundamental pattern for protecting your system from all manner of Integration Points problems. When there is a difficulty with them , stop calling them!
- Use together with Timeouts
- Expose, track, and report its state changes to Ops
MSDN's Circuit Breaker Pattern page is pretty good. Martin Fowler's introduction of Circuit Breaker with a simple example implementation in Ruby and useful links.
Impl. in Java with Spring AOP and JMX: https://code.google.com/p/jianwikis/wiki/CircuitBreakerDesignPattern, Clojure implementation.
Bulkheads
Bulkheads are water-tight compartments in a ship; when there is a hole, water floods only one compartment, saving the ship from sinking. Similarly you may partition your resources (servers etc.) and assign the partitions to particular clients/functions so that a failure doesn't affect all and/or more important functionality/clients are protected from failures triggered by less important ones. Physical redundancy is the most common form, protecting from HW failures. A small-scale example is binding a process to only a subset of CPUs. Inside of a process, you might create separate thread groups dedicated to different functions - f.ex. separate request-handling thread pool for administrative functionality. Ex.: A failure in flight status functionality won't stop check-in from working.
- The Bulkheads pattern partitions capacity to preserve partial functionality when bad things happen
- The partitioning leads to less efficient use of capacity (but virtualization might mitigate that into an extent - move VMs between the partitions on demand)
- Pick a useful granularity - thread pools inside an app, CPUs in a server, or servers in a cluster
- Very important with shared services model, when many systems depend in your application; you don't want to bring them all down when Chain Reactions happen
Steady State
For every mechanism that accumulates a resource (data in a DB, log files, memory consumed by a cache), some other mechanism must recycle that resource.
- Avoid fiddling - manual human intervention leads to problems; eliminate the need for recurring human intervention (disk cleanups, nightly restarts) through automation
- Purge data with application logic - an application knows better than DBA how to purge old data while preserving consistency and its sanity (f.ex. w.r.t. ORM)
- Limit the amount of memory a cache can consume so that it doesn't cause problems
- Roll the logs - don't keep an unlimited amount of log files, configure log file rotation based on size
Fail Fast
If a system can determine in advance that it will fail in an operation, it's better to fail fast.
- Avoid Slow Responses and Fail Fast - if you system cannot meet its SLA, inform the callers quickly without waiting for an error or timeout (<> Circuit Breaker)
- Reserve resources, verify Integration Points early - e.g. fail at once if a crucial CircuitBreaker is open
- Use for input validation - do basic user input validation even before you reserve resources not to waste them if f.ex. a required attribute is missing
- Ex.: Refuse a connection at once if there are already too many users in the system (=> throttling to a manageable level so that we keep a reasonable level of service for the users already there)
Handshaking
- signaling between devices that regulate communication between them; it protects the server by allowing it to throttle its own workload. Sadly, HTTP and RMI doesn't handshake well.
Create cooperative demand control - use client-server handshaking for demand throttling to serviceable levels; both must be built to support it
- Conside health checks as an application-level workaround for the lack of H., use where the cost of an additional call is much less than the cost of calling and failing
- Build H. into your own low-level protocols
Test Harness
A test harness emulates the remote system of an Integration Point and can simulate many errors (network, protocol, application-level) to test most/all of the failure modes. "A good test harness should be devious. It should be as nasty and vicious are real-world system will be." [126] "The test harness should act like a little hacker, trying all kinds of bad behavior to break callers." [128]
- A socket connection can be refused, sit in a listen queue until the caller times out, the remote end my reply with a SYN/ACK and then never send any data, it can send nothing but RESET packets, it may report a full receive window and never drain the data, the connection can be established, but the remote end never sends a byte of data, the conn.can be established but packets lost causing retransmit delays, conn.est. but the remote never ACK receiving a packet, causing endless retransmits, the service can accept a request, send response headers (supposing HTTP), and never send the response body; the srv can send 1 byte of the response every 30 sec; it can send HTML instead of the expected XML; it may send MB when kB of data expected; it can refuse all auth. credentials.
- Emulate out-of-spec failures
- Stress test caller - slow/no/garbage responses, ..
Decoupling Middleware
A well-done middleware integrates (by passing data and events) and decouples (by hiding specific knowledge, calls to other systems) systems.
Scale:
Same host, time, process
- In-process method calls
- Interprocess communication (shared mem, pipes, semaphores, ..)
- RPC (RMI, HTTP, ..) // same time, diff. host and process
- Message Oriented Middleware (MQ, SMTP, SMS, ..)
- Tuple Spaces (Java/Giga/T Spaces)
Different time, host, process
- Decide at the last responsible moment; this is an architecture decision that is expensive to change
- Avoid many failure modes though total decoupling (of servers, layers, applications)
- Learn many architectures, and choose among them
Quiz - what is wrong here:
try { ... }
finally {
if (stmt != null) stmt.close();
if (conn != null) conn.close();
}
- stmt may rarely throw an exception and the conn will thus never be closed, leading to connection pool exhaustion
Capacity
User sessions are the Achilles heel - they consume memory, and, if replication enabled, CPU and bandwidth.
Load testing: real world isn't polite to the site. Search engine spiders may ignore cookies create a new session on each request (while generating many requests). Scrapers and shopbots do the same.
=> don't test the system just the way it is meant to be used
Useful tools
- If every request creates a session, verify the client handles cookies properly and send those who don't to a "how to enable cookies" page
- Capability to cap the number of requests to the system so that we can keep sessions below the crash limit
- Detect and block IPs, subnets etc. that create evil traffic
Capacity
- Performance: how fast the sys processes a single transaction
- Throughput: # tx / a time span
- Scalability: 1) throughput as f(load); 2) how the systems can be scaled up by adding capacity
- Capacity: the max throughput the sys can sustain, for a given workload, while maintaining an acceptable response time for each individual tx (the workload may change radically e.g. when users are interested in different services during a particular season)
- Constraint: There is always one (current) constraint <> theory of constraints
Capacity myths: CPU, bandwidth, and storage are cheap.
Capacity antipatterns
9.1 Resource Pool Contention
"Used well, [DB] connection pools, like all resource pools, can improve capacity by improving throughput. Left untended, however, resource pools can quickly become the biggest bottleneck in an application." [167] - when there is contention for the resource , i.e. less than needed available; the requesting thread is then blocked indefinitely. Also, each connection - even whine idle - consumes resources on the remote system.
- Eliminate Contention under normal load
- If possible, size resource pools to the request thread pool
- Prevent vicious cycles: contention => tx take longer => more contention
- Watch for the Blocked Threads pattern (capacity => stability issues)
Excessive JSP fragments
AJAX Overkill
Ajax = many more requests coming from the browser to the server, more rapidly. The req and resp will typically be smaller. Used poorly, it will place more burden on the web an app servers.
Session thrashing - ensure session affinity so AJAX req go to the server having the user's session. Make sure you don't create a new session for each req.
Overstaying Sessions
How long a session stays in mem after the last req (as we have now way of knowing the user went away for good) - defaul(ed) to 30min in Java. Look at your data to determine session timeout: e.g. avg + 1 std dev. In practice it will be ~ 10 min for a retail site, 5 min for a media gateway, up to 25 for travel-industry sites. Even better is to make sessions unnecessary. F.ex. in-mem copy of persistent data may be dropped and recreated at any time (keep keys, not whole objects).
Wasted space in HTML
Every byte consumes bandwidth, memory, processing resources on different networking equipment and the servers. Omit needless characters, remove whitespace, replace HTML tables with CSS layout.
The Reload button
If the site is slow, users may start hitting Reload in hope of getting a presumabely stuck response, thus increasing the load even more. (The app server doesn't know it should stop processing the previous one.) Make your site fast so that users never think of doing this.
Handcrafted SQL
ORM => predictable, repetitive SQL. Predictable access patterns of SQL are good for capacity, b/c a competent DBA can tune the DB for them. OO developers suck at relational queries and create expensive queries inconsistent with the tuning for the rest of the app.
Common problems: joins on non-indexed columns, joining too many tables, .. .
=> minimize, check with a DBA, verify gains against real data.
DB Eutrophication
- slow buildup of sludge that eventually kills it
Create indexes
- Purge sludge = old data (mv from prod servers elsewhere, ...)
- Keep reports out of Prod
Integration Point Latency
Calling a remote point takes time + its processing time, don't ignore that. A performance issue at first may become capacity issue of the whole system. Avoid chatty remote protocols.
Cookie Monsters
=> keep cookies small; they're sent with every request.
Capacity Patterns
Pool Connections
Use & remember to protect callers from blocking forever. Size them for max throughput.
Use Caching Carefully
Limit cache sizes. Build a flush mechanism. Don't cache trivila objects. Compare access and change frequency.
Precompute content
Not everything needs to be dynamic and even not all the dynamic stuff changes equally often.
Tune the garbage collector
"In Java applications, garbage collection tuning is the quickest, and easiest way to see some capacity improvements. An untuned application running at production volumes and traffic will probably spend 10% of its time collecting garbage. That should be reduced to 2% or less." [205] (Remember this was written in 2007.)
PART IV General Design Issues
11. Networking
Topics: Multihomed servers, getting routing right, virtual IP addresses.
12. Security
Topics: The Principle of Least Privilege (separate user/app, ...), Configured Passwords (separately in encrypted files, ...).
13. Availability
Gathering and documenting requirements (refer to these whenever responsible for defining availability!), load balancing, reverse proxying, clustering .
14. Administration
Does QA match production?
Keeps app separated if sep. in prod to prevent hidden dependencies. Zero, One, Many - if having many nodes in prod, have 2 in QA. Just buy the gear: "I've seen hours of downtime result from presence of firewalls or load balancers in production that did not exist in QA." [238]
14.s Start-up and Shutdown
Build a clear start-up sequence into the app so that everything starts in the right order and must complete before requests are served. Init. at least some conn for each conn. pool (Fail Fast).
Clean shutdown: have a mode where existing tx are completed (remember a timeout) but new request not accepted.
CLI interfaces for administration are best (<> scripting) x GUIs.
PART IV Operations
17 Transparency
= qualities allowing personnel to gain insight into the system's historical trends, present conditions, instantaneous state, and future projections.
Perspectives
- Historical Trending - system and biz level metrics in the OpsDB => trends
- Predicting the future (how many users can we handle, ..)
- Present status - the state of each app and HW - mem, garbage coll. (frequency ,..), threads for each pool, DB conn pools, traffic stats for each request channel, biz tx for each type, users (demographics, #, usage patterns, errors encountered, ...), Integration points, circuit breakers
- instantaneous behavior a.k.a. what the *** is going on? <> monitoring systems, thread dumps, stack traces, errors in log files, ...
Designing for Transparency
Start early. You need visibility into the whole system to avoid local optimization.
Enabling Technologies
Logging
- Configurable location (=> a different drive)
- Levels: only log as error/sever what requires attention from Ops; not every exception is an error
- Catalog of messages (asked for by ops) - use the internationalization tool in your IDE to produce it easily; include keys for easy lookup - e.g. the created i8n keys => unique, easy to lookup
- Human factor: convey clear, accurate, actionable information so that humans under stress can interpret it correctly; make it readable for humans and their pattern-matching ability
- Include ID of the transaction to track it across components
Monitoring systems
Standards
- SNMP - widely supported, old; supporting a custom SW is laborious
- CIM (1996, successor to SNMP) - more dynamic, superior; not too widespread
- JMX - great for JVM-based apps
What to expose
- Traffic indicators: page requests [total], tx counts, concurrent sessions
- Resource pool health: enabled state, total resources, r. checked out, high-water mark, # r. created/destroyed, # times checked out, # threads blocked waiting for r., # times a thread has blocked
- DB connection health: # SQL exceptions, # queries, avg response time to q.
- Integration point health: state of circuit breaker, # timeouts, # requests, avg response time, # good responses, # network/protocol/app errors, IP address of the remote endpoint, current # concurrent requests, concurrent req. high-water mark
- Cache health: items in c., memory used by c., cache hit rate, items flushed by garbage collector, configured upper limit, time spent creating items
Operations Database (OpsDB)
Logging & monitoring expose the immediate behavior/status but unsuitable for the historical/future perspective => accumulate status, metrics in a (ops) DB.
OpsDB high-level structure
*|-|*
/-1-Node-*-(needs)*-Feature
*|
Observation-*-1-Observation Type
|
- one of Measurement, Event, Status
- Feature - a unit of biz-significant functionality (related to avail SLAs); typically implemented across multiple hosts (web, app, DB, ..), network equipment such as FW, switch etc. - Node represents any of these active nodes (typically it suffices to represent hosts and apps). Optionally track what nodes use other nodes.
- Observations: Measurements are mostly periodic performance stats; Statuses are state transitions (c.breaker on/off, ...). ObservationType defines the name and concrete subtype of the Obs.
Eventually we add:
/-1-ObservationType
1|
Expectation-*-1-ExpectationType
|
- one of NominalRange, ExpectedTime, ExpectedStatus
Expectation = an allowed range for a metric, a time frame in which an event must [not] occur, an allowed status; violation => alert. Set based on historical data. (Beware false positives = crying the wolf!). Eventually the expectation values may become functions of the business rhythm (day/night, special seasons, ...)
Supporting processes
Build an effective feedback process, i.e. only share meaningful data that is act on responsively . See Plan-Do-Check-Act, Boyd's OODA etc.
Keys to Observation
Watch for both trends and outliers. Include continuous improvement.
- Every week, review the past w. problems, look for recurring ones and most time consuming ones, for particular troublesome subsystems/3rd party/integr.point.
- Every month, look at the total volume of problems, consider the distribution of pr. types. The trends should be decrease in severity and volume.
- Daily or weekly look for exceptions, stack traces in logs => find most common sources, consider whether they indicate serious problems or gaps in error handling.
- Review help desk calls for common issues => UI improvements, more robustness
- If there are too many problems to review, look for top categories and sample them randomly
- Every 4-6 months, recheck that old correlations still hold true
- At least monthly look at data volumes and query stats
- Check the DB for the most expensive queries; have their q. plans changed? Is there a new €€€ query? <=> accumulation of data somewhere. Check for table scans => missing indices.
- Look at the daily and weekly envelope of demand and sys metrics; are traffic patterns changing? if a popular time is dropping in popularity, the sys is probably too slow at those times; if there is a plateau then perhaps there is a limiting factor, e.g. responsiveness of the system.
The emphasis shifts from reactive to predictive. Old metrics/reports loose value.
For each metric being reviewed: How does it compare to the historical norms? If the trend continues, what happens to the correlated metric (# users x responsiveness); how long can it continue before hitting a limiting factor and what will happen then? => interpretation & decisions
18. Adaptation
Topics: Adaptatable SW design, dependency injection, object design, XP coding practices, agile DBs, adaptable enterprise architecture, dependencies within a system, d. between systems: protocols/DBs, releases shouldn't hurt (0 downtime deployments, ...)